Table of Contents
I previously wrote about why, and a high-level version of how, I built an AI agent for my fantasy league. There is so much more under the hood to cover in this post.
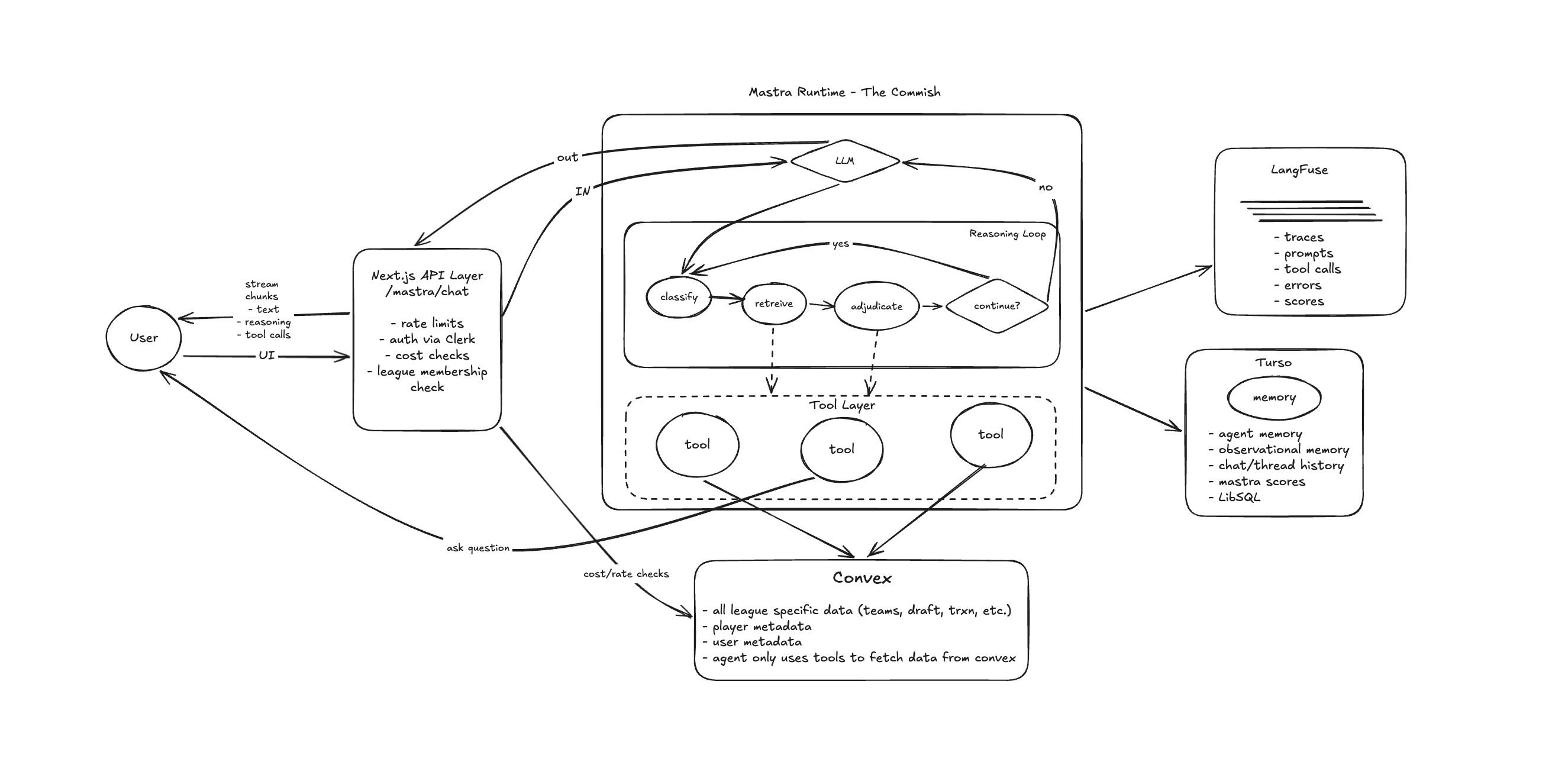
Quite a bit has changed since that last write-up. I am now using Mastra as the agent framework, and the biggest lesson has been this: the harness (the gates, context, tools, and memory around the model) matters more than the model itself.
We are still in the early stages of figuring out harness engineering, so some of this might look different a few months from now, but this is what is working today.
AI agents are quickly changing how users interact with software. Their rapid improvement comes from both advances in LLM models and the agent harness. The harness is the system built around the LLM, and its goal is to give the model the right context and tools so it can make the best decision possible.
For The Commish, that means tools to fetch league- and user-specific data from Convex so Commish can respond as accurately as possible. A user can be in multiple leagues with different rosters, salary caps, and opponents. The agent must never leak context across leagues, so league scoping is enforced at the infra layer, not the context layer.
API Layer
At the time of writing, the Commish entry point is chat in the Ask Commish tab. From there, we have a Next.js API layer where chat calls a /mastra/chat endpoint. Before the model sees anything, we run strict gates on auth, schema validation, league membership, rate limits, and spend limits.
The route configures the agent with a 12-step limit, enables reasoning, and injects system context. The step limit bounds inference cost per turn. Reasoning traces help debug tool-selection decisions in Langfuse.
I pass leagueId, userId, and threadId through RequestContext, so tools do not trust client-supplied identifiers. Then I inject system context for my team resolution so the agent can resolve references without asking follow-up questions.
Memory is scoped by threadId (conversation) and resourceId (userId:leagueId) so history stays isolated per user per league. I intentionally keep memory conservative:
- only the last 10 messages are recalled (
lastMessages: 10) - semantic recall is disabled (
semanticRecall: false) - user preferences like "call me X" are extracted with deterministic regex rules instead of another model call
That reduces context bloat, lowers cost, and makes behavior more predictable turn-to-turn.
In this setup, semantic recall is disabled mostly for control and reliability. Current state should come from tools, not memory. League standings, rosters, contracts, and transactions are dynamic and authoritative in Convex. Semantic recall can surface old state.
Similarity search can also pull in loosely related prior turns, which bloats prompt context and distracts the model from the current question. Semantic recall adds retrieval work and often more tokens.
If you want longer-horizon personalization or continuity (for example, "remember my strategy from last month"), then enable it with strict filters and recency weighting. For Commish's current goal (accurate, turn-specific analysis), disabling it is the safer default.
Reasoning Loop
The Commish reasoning loop is a six-step process. I will break down each step:
- Classify Intent
- Resolve Scope/Context
- Fetch Evidence
- Adjudicate
- Decide Next Action
- Respond and Persist
1. Classify Intent
When a user sends a prompt, the agent's first order of business is to classify the prompt's intent. Is this a question about standings? A trade analysis? A rules question? A roster deep-dive?
This is not an explicit classification step in code. There is no intent router or switch statement. The LLM reads the system prompt, tool descriptions, and user message, then decides what kind of question it is looking at. The tool descriptions do most of the steering here.
For example, the getLeagueStandings tool description states:
League standings with records and points. Start here for competitive questions - contenders, power rankings, who's winning - before drilling into individual teams or financials.
And the getTeamRosterSummary tool description is:
Compact team overview: position counts, top players, and weak spots. Start here for any team-specific question - only drill into
getTeamRosterif you need individual player contract breakdowns.
The model reads those and self-routes. I could have built a separate classifier that picks a tool path, but encoding the routing logic into tool descriptions means I have one surface to maintain and the agent adapts to ambiguous prompts more easily. I might find that a classifier is needed later, but the goal is to keep things simple first and add complexity only when required.
2. Resolve Scope/Context
Before fetching data, the agent needs to know whose data to fetch. This is where injected system context does most of the work.
Before the agent even runs, the API layer has already looked up which team the user manages and injected it:
This user manages the team 'Team Name'. When they ask about 'my team', they are referring to 'Team Name'.
That single injection eliminates the most common ambiguity. Without it, nearly every question starting with "my" would require a clarification round-trip.
When injected context is not enough (for example, the user asks about a trade but does not say which teams), the agent has a dedicated askUserQuestion tool.
This is not a prompt trick where the model just says "can you clarify?" in its response. It is a real tool call that persists a structured clarification record to Convex with the question, multiple-choice options, and a reason.
The tool description tells the agent to stop after calling it, which prevents it from guessing and attempting partial analysis.
When the user responds, the API layer detects the open clarification, marks it answered, and injects the resolved Q&A as system context:
[Clarification: "Which teams?" -> "Mine and the Sharks"]
The agent sees the answer as structured context, not buried in conversational back-and-forth.
There is also an anti-loop guard: if the user already answered a clarification this turn, the tool throws an error if called again. The agent has to work with what it got.
This was a deliberate constraint. Without it, I found the agent would sometimes ask two or three clarifications in sequence, or ask the same question repeatedly, instead of making a reasonable assumption.
The multiple-choice defaults are worth mentioning. If the agent does not provide choices, the tool generates contextually appropriate ones by keyword-matching the question.
Trade questions get trade-specific options ("My pending trade offer", "A hypothetical trade I am considering"). Team questions get team-specific options. This reduces friction for the user and gives the agent structured input for the next turn.
3. Fetch Evidence
This is where progressive disclosure kicks in. Tools are designed in layers: cheap summaries first, expensive details only when summaries are not enough.
getTeamRosterSummary returns position counts, top three players by salary, and weak positions - maybe 200 tokens.
getTeamRoster returns every player with full contract details - easily 800+ tokens for a deep roster.
The system prompt tells the agent to start with summaries, and tool descriptions reinforce it ("only drill into getTeamRoster if you need individual player contract breakdowns").
This matters for two reasons:
- Tokens cost money, and every token in the context window also costs reasoning quality.
- Latency improves because summary tools return faster and require fewer round-trips.
The maxSteps: 12 ceiling is generous enough that the agent can chain 4-6 tool calls for a complex trade comparison, but in production it rarely goes past 6.
A typical "how's my team doing?" question resolves in 2-3 steps: standings, roster summary, respond.
One thing I found in practice: progressive disclosure works better when tool descriptions explicitly say when not to use the expensive tool. "Only use after getTeamRosterSummary" on the full roster tool was more effective than just saying "use summaries first" in the system prompt.
The model pays more attention to the tool description it is about to call than to a general instruction it read 2,000 tokens earlier.
4. Adjudicate
Once the agent has data, it reasons about it. This is the part the LLM is actually good at: synthesizing structured data into an assessment.
But I found one persistent bias I had to correct in the system prompt: the model over-indexes on salary numbers. When a tool returns salary and contract data, the model's default instinct is to treat high-salary players as better and low-salary players as worse.
In a salary-cap dynasty league, that is often backward. A great player on a cheap contract is more valuable than a great player on an expensive one.
So the system prompt explicitly says:
Judge teams by roster talent and depth first. Use cap and contracts as supporting context, never as the primary signal.
That single instruction improved trade and roster analysis quality significantly.
Note: This is still far from perfect. Once we have player stats, this specific scenario will be much easier to evaluate accurately.
The key takeaway: the agent can make better decisions when it has the right data and the right evaluation frame.
5. Decide Next Action
After reasoning, the agent decides: do I have enough to answer, do I need more data, should I escalate, or should I ask a clarification?
This is the loop part of the reasoning loop. The agent might go back to step 3 and fetch more evidence.
The maxSteps: 12 bound ensures this cannot run forever, but in practice the agent self-terminates much earlier because the system prompt says:
If critical info is missing, ask one clarifying question and stop that turn.
6. Respond and Persist
The agent generates a final response, which streams to the user via createUIMessageStreamResponse.
The response is persisted to Mastra memory (backed by Turso/LibSQL), scoped to thread and resource. The 10-message window means old context drops off naturally so the prompt does not grow forever.
After the stream closes, cost tracking fires asynchronously.
The onStepFinish callback accumulates per-step cost from OpenRouter provider metadata across the full reasoning loop, and the total gets logged to Convex with the model ID, league, and thread.
The user never waits for this. PostHog captures commish_message_sent with cost and model for analytics.
Observability
An agent that calls tools, reasons over structured data, and makes multi-step decisions is a black box unless you can trace what happened inside each turn.
I use Langfuse for this. Every agent invocation, tool call, and reasoning step is exported as a trace with userId as the context key.
When a user reports an incorrect answer, I can walk through the full path in Langfuse:
- which tools did it call
- what data came back
- what did the model reason about
- where did it go wrong
Usually the answer is one of three things:
- The agent called the right tool but misinterpreted the result.
- The agent called the wrong tool first and ran out of useful context by the time it corrected.
- The agent skipped a tool call entirely and confabulated.
Each failure mode has a different fix: tool description tweak, system prompt adjustment, or schema change. Without trace data, you are guessing.
I also run two inline scorers on production traffic.
Answer relevancy runs on 25% of responses; it checks whether the answer actually addresses the user's question.
Toxicity runs on 100% of responses. That is intentional: Commish's persona encourages sarcasm and trash talk, and the line between friendly ribbing and being genuinely rude is narrow enough that I want every response checked.
Both scorers use a cheap eval model (gpt-5-nano via OpenRouter), so cost is negligible relative to primary inference.
The relevancy sampling rate is configurable. I can dial it up to 100% when investigating a quality regression, or reduce it once I am confident in a model change.
Cost as a Design Constraint
When you are paying for inference on behalf of users, cost is not just a monitoring metric - it is a design constraint.
Every architectural decision in the harness has a cost implication.
The progressive-disclosure pattern (summary tools before detail tools) exists partly to reduce token count. The 10-message memory window exists partly to keep prompt size bounded. Disabling semantic recall exists partly to avoid retrieval tokens.
These are not afterthoughts. They are cost decisions.
On top of that, I enforce two per-user spend limits:
- a 4-hour rolling window
- a 7-day rolling window
Both are checked before the agent runs. If a user hits the 4-hour cap, they get a structured response with the exact reset time. If they hit the 7-day cap, same thing.
This protects against both abuse and honest overuse. A user deep in trade analysis during deadline week can easily rack up a dozen complex multi-tool conversations. I am not here to subsidize unlimited inference for my league mates.
Cost tracking is granular. OpenRouter returns per-request cost in provider metadata, and I accumulate that across every step of the reasoning loop via onStepFinish.
After the stream closes, total cost for that turn is logged to Convex with model ID, league, and thread.
That means I can answer questions like "what is the average cost per conversation turn?" and "which model is most cost-efficient for the quality we need?" with real production data, not estimates.
What's Next
The Commish today is a read-only analyst. It fetches data, reasons, and responds. That is useful, but it is also a ceiling.
There are three things I am working on next that expand what the agent can do.
Real-time player intelligence. Right now Commish knows everything about your league (rosters, contracts, standings, transactions), but it knows nothing about the real world. It cannot tell you that a player is injured, trending on waivers, or having a breakout week.
I am adding a web-search tool via Exa MCP so the agent can pull real-time player news when reasoning about roster decisions. I am also working on pulling and storing player stats via an API.
This part is crucial for the league regardless of whether an agent uses the data, and it should also improve response accuracy.
This changes reasoning in a meaningful way. Today, when you ask "should I start Player X?", Commish can discuss contract and roster context but has to avoid real-world performance prediction. The system prompt currently says "You don't predict real-world fantasy performance."
With real-time data flowing in, that boundary moves. The agent can factor in injury reports, matchup data, and recent production alongside the league-specific context it already has.
Write tools. The bigger architectural shift is introducing tools that mutate state: setting lineups, submitting waiver claims, and proposing trades.
Today every tool is read-only (client.query). Write tools (client.mutation) change the trust model entirely.
A bad read returns wrong information. A bad write drops the wrong player.
That means tighter confirmation flows, undo semantics, and likely a separate permission tier where users explicitly opt in to agent actions. I do not want Commish dropping a player because it misunderstood a hypothetical as a directive.
The same harness patterns in this post (tool descriptions as routing, progressive disclosure, clarification loops, escalation) carry over to a write-capable agent. But the cost of a wrong decision goes up, so the guardrails have to go up with it.
That is the next engineering problem to solve.
Imagine a Claude Code-style product for your fantasy football league. That is what this can become.
Rather than sorting through waivers for hours or debating who to start, you start a conversation with The Commish, let it perform the research and analysis, then approve actions based on that work.
Call it "Vibe Fantasy Football." It does not really roll off the tongue though.
If you made it this far, I am impressed and truly grateful for your time.
Please reach out via email (will@inferencepartners.ai) or on X (wrowston).
You can also join the waitlist for the future of fantasy football at onlyfootballfans.football.